Some posts only go to subscribers via email. EXCLUSIVELY.
You can read more here or simply subscribe:
GPT vs. Claude: An AI Writing Showdown
There’s a new kid on the AI block, and his name is Claude. Claude is an LLM (Large Language Model) by Anthropic and lives here.
I work with ChatGPT a lot, and the experience has been a bit disappointing lately. According to the rumors, its reasoning skills are deteriorating due to OpenAI’s added layers and tweaks.
This YouTube lecture by Prof. Sebastian Bubeck, shows how early training of GPT4 for safety dumbed it down. Maybe they’re doing more of that?
All I know is that as a user, I wish I could access the March 2023 version of ChatGPT with GPT4. I miss that guy.
Anyway, I heard many good things about Claude, so a couple of weeks ago I created an account (it’s free) and started playing around.
How does Claude compare to ChatGPT?
I really like Claude. It’s a great AI with a good “out of the box” writing style.
ChatGPT’s default style tends to be more formal and feel “stuffed.” It often reminds me of a high-school composition. Of course, you can change that with a little bit of prompting. ChatGPT can mimic any style you want and do that very well.
Let’s get technical for a minute
I am not an expert on AI, so the following is only “to the best of my understanding.”
Both Claude and GPT (whether 3.5 or 4) are large language models operating on a similar principle: They’ve been trained using vast datasets to perform natural language processing tasks.
From everything I’ve read, Claude has been trained on 175 billion parameters, which is on par with GPT3.5. Nobody knows the exact number of parameters used for GPT4, but rumors point to 1.76 trillion. That’s roughly ten times the number of parameters.
However, the number of parameters isn’t the end-all-be-all when assessing an AI’s capabilities. It can hint at the extent of the model’s knowledge, but there’s much more to consider.
Considering just the number of parameters, you might expect ChatGPT with GPT4 to be “smarter” or more “knowledgeable” than Claude.
However, it appears that Claude has been designed with a specific focus on writing tasks, making it particularly skilled at that job. GPT4’s abilities are more general.
While it can write exceptionally well, its massive “brain” is equipped to do much more, broadening its range but potentially diluting its specialization in any one area, such as writing.
I put these AIs to the test
My company creates articles for websites. We rely on AI to do the heavy lifting of writing these days. We have a team of content specialists who are trained in wrangling the AI to produce articles.
Our content specialists typically use Koala to create the first draft of informational content. They sometimes use ChatGPT, with GPT4, to create additional sections or craft specific articles that Koala doesn’t support.
Whether using Koala or ChatGPT, they fact-check and edit everything, following the method I explained in detail here.
I was curious to see if ChatGPT with GPT4 was still the best choice in August 2023. Maybe we can go back to the (cheaper and faster) GPT3.5 version? Or maybe we should utilize Claude?
A writing competition!
I decided to test the three models –
- ChatGPT with GPT3.5
- ChatGPT with GPT4
- Claude
This was the prompt they were given –
You are tasked with writing a brief informational response to one of the following questions. Your answer should be concise, clear, and factually accurate, providing a complete response to the question in a few sentences or a short paragraph.
Your topic is –
Guidelines:
Length: Your response should be between 100 to 150 words. It should be long enough to adequately answer the question, but concise enough to demonstrate your ability to convey information succinctly.
Tone: Use a neutral and informative tone. This exercise does not require personal opinions or embellishments.
Content: Focus on providing factual information relevant to the question. Citations are not required for this exercise, but ensure that the information is generally accepted and true.
Language: Write in clear and grammatically correct English. Avoid jargon unless it is common in the field and provides necessary context.
Format: Please write your response in plain text.
I tried this prompt with five different topics. The topics were –
- How Does a Savings Account Differ from a Checking Account?
- What is the AKC, and What Role Does It Play in Dog Breeding?
- What Is the Role of a Fashion Stylist in a Photoshoot?
- What Are the Basic Principles of Lean Six Sigma?
- What are some of the most popular Israeli children’s television shows that aired in the 1970s?
Topic #5 is deliberately obscure. I wanted to see the AI’s extent of knowledge and test their behavior when asked something they’re unsure about.
Introducing the Judges
The experiment began when I decided to let ChatGPT evaluate Claude’s output, just for fun. It gave a pretty decent evaluation and explained the strengths and weaknesses of the text.
Since I didn’t have the time to evaluate multiple “submissions” in-depth, I decided to let the three AI models do the heavy lifting here as well. Each model was asked to evaluate all three responses to each prompt and score them between 0 and 100.
In a separate thread, of course. They were not told this was AI content or who created what text.
I even had Midjourney take a picture of the event –

The results were interesting
All three AIs generated decent results. The AI judges gave fairly high scores across the board. 80 points was the lowest score given by an AI.
The models didn’t seem able to recognize or otherwise favor their own writing. Hardly surprising but still funny for a human to observe (at least it was for me).
Overall, the winner – based on the decision of the esteemed AI judges – was ChatGPT with GPT4.
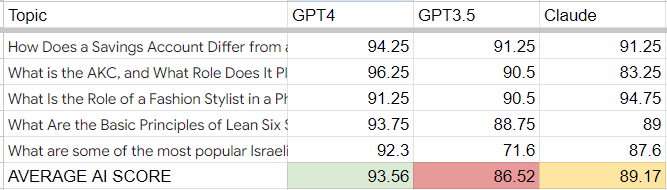
Claude came second, with GPT3.5 trailing behind.
The Human Verdict
I was curious to see how humans would feel about the same texts. I didn’t want to take up too much of people’s time, so I only shared the AI writing samples covering the question of Checking vs. Savings accounts.
I shared those with a few other publishers, one of our editors, and whoever wanted to chime in on Twitter. Check it out if you want to see a sample of the actual texts. In total, eight people scored the texts.
Human critics proved to be harsher than AI. Here are the results, based on the human judges –
- ChatGPT with GPT4 – 73.75
- ChatGPT with GPT3.5 – 63.125
- Claude – 65.5
Interestingly, the AIs and the humans reached the same conclusions (albeit with different scores).
The “obscure knowledge” topic
I deliberately chose one obscure topic: Israeli children’s TV shows in the 1970s. I wanted to test the extent of the models’ knowledge and what would happen if they didn’t know the answer.
None of the AIs managed to give an accurate answer. But there were levels of “wrong.”
GPT4 gave the best answer. It mentioned three shows. All shows were Israeli children’s TV shows, but two aired for the first time in the early 1980s.
GPT3.5 mentioned three shows as well. All three shows were real, but two were not children’s TV shows and none aired in the 1970s.
As for Claude, he mentioned two children’s shows from the 1980s and then completely hallucinated a third show. It came up with a name that sounds like Hebrew, but the first word was gibberish and the second meant “little.”
It makes sense when you consider the extent of datasets that GPT4 was trained on.
So – which AI to use?
Overall, they are all pretty great. Seriously, the level of writing produced by these LLM’s is astounding.
Fact-checking aside, if a writer were to apply to our team a year ago displaying this level of writing, we would hire them. And that’s before we talk about the speed of delivery. Also, you don’t have to wonder if they used AI to produce content while charging you the full writing price.
Considering the results – and mostly my own intuition – we’ll continue using GPT4 for writing articles. Our content specialists know how to prompt it to deliver the tone they’re looking for. In terms of depth, structure, and accuracy, it’s the better AI of the three.
Specifically, my concern with Claude and GPT3.5 would be accuracy. Or lack of. Granted, you should always fact-check AI content. That’s what we do – even with GPT4. But GPT4 will need fewer corrections, and I just trust it more.
What about the cost?
For my needs, it doesn’t matter that GPT4 isn’t free.
I’m running a business. Investing $20 a month for 50 messages every three hours is a negligible expense.
The same goes for using Koala. Yes, it’s far more expensive, but it’s a huge time saver for my team.
It’s either paying Koala or having to spend more time on articles. It’s not just the question of the immediate expense. I prefer not to put people through a grind if I can avoid it.
And in general, I’m of the mind you should invest money to make money.
The best solution for most of our articles is still Koala, using GPT4 and internet search results. We rarely have to correct any facts, and – with the right settings for our needs – editing is typically minimal. Most of the work is to reduce fluff and redundant sections. Other than that, Koala GPT4 articles are usually pretty good.
But, as always, your mileage may vary.
Your tech stack may be different than mine, and that’s fine. Maybe Claude works better for your needs, or maybe it’s ChatGPT. Or maybe you write your own content. I still do that here on Yeys, and it’s still the right solution for some types of content.
By the way, I do let ChatGPT read these posts and suggest edits. What you’re reading here today is Human-Generated AI-Assisted content. I hope you enjoyed the end result!
Who’s your favorite AI Writer?
I’d love to hear about your own choice of AI these days. Who do you use and why? Let me know if it’s ChatGPT or Koala, GPT4, GPT3.5, Claude, or who knows… maybe there’s a Bard fan out there? Eager to read the comments.
I had been using ChatGPT4 to create a lot of content, and even write whole books. It started to seem, however, that the output was getting stingy and the text less complete, elaborate, and interesting. I stopped paying. ChatGPT 3.5 is doing well enough. I found this article looking for insight into the paid version of Claude. Is it worth the $20/month compared to ChatGPT4? I think I’ll have to do my own experiment, but so far it seems like the free versions are equal.
I do like Bard. It sometimes comes up with content that’s equal to the other free versions when it’s about general information topics. It makes good lesson plans. My hope is that Google makes Bard better than ChatGPT4 and bundles it into the second tier paid version of Google Workspace for $20/month. I love how it integrates into Google Docs, but it doesn’t usually work, unfortunately. The potential is there to be the best, but it’s not even close now. It would save me a lot of tedious copying, pasting, and reformatting.
Hi Joe, I agree Bard holds a lot of potential if it gets integrated properly into other Google products. Like you said, it’s not there yet. I’ve been trying it with Gmail and access to Drive too.
ChatGPT Plus offers multiple add-ons now that I’m liking a lot, especially voice and the ability to “see” images. Very helpful, when combined with the reasoning skills of GPT4, so I’m sticking to it. Also, as this experimentation showed, people still prefer the GPT4 output over GPT3.5, so again, I’m sticking with that for now
Hi Anne,
Exploring the Future of Information Search and Your Impressive Portfolio.
I recently had the pleasure of watching one of your interviews on YouTube. While I’m not a blogger myself, I have some experience in journalism, having written travel reportages and interviews for Elle in my younger days. Your work sparked my curiosity in the evolving world of blogging, SEO, and the broader infobusiness landscape.
I am very interested in exploring some of the 25 websites you’ve developed. Could you kindly share where I might find them? Your perspective on this matter would be greatly enlightening.
Additionally, I’m intrigued by your thoughts on the future of information searches. Do you foresee humans continuing to rely on traditional search engines like Google for insights found in blogs? Or will there be a shift towards AI-driven platforms such as Bing, Bar, and ChatGPT, which seem to be reshaping how we access information?
Congratulations on your remarkable achievements in this dynamic field. Your insights would be invaluable to someone like me, who is keen to understand the direction in which our digital world is headed.
Best regards,
Eduardo Cortes
Norway
Hi Eduardo,
Good question about search vs. AI in the future. My personal view is that people will eventually transition to AI-based answers, but I suspect this may only happen when we have personalized AI assistants that are easy for average people to operate. There are privacy concerns around those, so I’m not entirely sure when that will happen.
As for examples of my sites, I prefer not to share those here, sorry, to avoid people trying to copy them or pursue negative SEO attacks.